
In my latest DevOps and AI experiment, I deployed two powerful open-source language models — Deploying DeepSeek-8b and DeepSeek-32b on MicroK8s — on a Kubernetes cluster using MicroK8s. This hands-on setup allowed me to explore performance characteristics, resource consumption, and architectural implications of running large-scale models locally without relying on cloud GPUs.
Hardware Environment: Deploying DeepSeek-8b and DeepSeek-32b on MicroK8s
The deployment was hosted on a Dell R720 server with the following specifications:
-
40 CPUs
-
128 GB RAM
-
3 TB Storage
For optimized performance, I allocated 36 CPUs specifically for Ollama, the lightweight framework responsible for serving the DeepSeek models.
Deployment Stack Overview
The following technologies formed the core of my deployment architecture:
-
MicroK8s – A lightweight Kubernetes distribution ideal for local and edge deployments.
-
Ollama – Used for efficiently serving LLMs in a containerized setup.
-
Open WebUI – Offered a clean, user-friendly interface to interact with the models.
-
Persistent Volumes – Ensured stable, consistent data storage across pods.
-
LoadBalancer Services – Enabled external access to the cluster’s internal services.
Observations and Model Comparison
Both DeepSeek-8b and DeepSeek-32b were tested using identical prompts. Here are my key findings:
-
DeepSeek-8b:
Produced long, descriptive responses — ideal for exploratory tasks and creative writing. -
DeepSeek-32b:
Delivered concise, accurate, and well-structured answers, making it better suited for high-stakes or professional use cases. -
Performance Trade-Off:
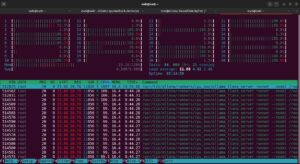
The 32b model took roughly 10 minutes to generate a complete response, demonstrating the computational demands of larger models, especially when run without GPU acceleration.
This side-by-side comparison offered valuable insights into the trade-offs between model size, accuracy, and compute cost.
Conclusion
This project extended beyond deploying language models. It was a comprehensive exercise in managing AI workloads within a Kubernetes-powered production environment. Leveraging local bare-metal infrastructure, I successfully created a cost-effective, cloud-independent AI setup.
There’s still room for optimization, but this deployment lays a strong foundation for future experiments with local LLMs and edge AI systems.
Are you exploring similar setups? Feel free to connect — I’m always open to sharing experiences and learning from others in this space.
Visit My Website: Mjunaid
Visit My LinkedIn: Click Here